总之重构了我的博客
前言:我的博客变迁史(?)
前博客时代
很早就有写博客的想法,但当时一点前端也不懂,又懒得学。一拍脑瓜决定用Github的Issue充当简易博客:支持基本markdown,能用标签分类,顺便也支持评论。这样一看其实博客该有的功能差不多都有了,于是2020年开始就在这个仓库里用issue写博客。除了好像寒酸点,似乎没啥不好。
然而彼时的github的issue并不支持LaTeX,我又有些写数学相关内容的需求。所以有些数学相关的内容想了想就放到知乎上了,期间也写了点回答。知乎上我的第一个回答是如何直观地理解阿贝尔变换恒等式?Locietta的回答,我对这个回答还挺满意的()实际上也是整理了高中的时候研究过的前向差分到阿贝尔变换的过程,算是大二的我对高中数竞历程的一次回顾吧。数竞经历给我留下的也只有这点零碎的边角料了。
那之后在知乎上也放了几篇关于数值分析的文章,还有几篇关于WSL配置和MSYS2的编程相关内容,这个时期知乎算是充当了我的博客了,而原来的issue仓库就逐渐被我冷落了下来。
真正意义上的博客
大概到了2022年年底,那会恰好比较闲,我想着要不搭个自己的博客网站吧。正好那段时间又感觉知乎的环境在变差,几个关注的写技术文章的人离开了,就感觉还是得有个自己的地方放东西。有没有人看倒没有太所谓,很多时候写文章本身就是很好的提升自己的机会(You should blog even if you have no readers)。刚好手头上还有个闲置的locietta.xyz的域名,那时候只用laptop.locietta.xyz来做DDNS好让我能用固定域名远程到笔记本。说实话有点浪费,就开了个blog.locietta.xyz准备用作新博客的域名。
如前文所说,那时我完全没有前端经验(现在也是)。当时接触的也就是软件工程课上的小组作业(在人家搭好的antd框架里写点逻辑),以及图形学课上自己拿webgl写的小东西。搭建博客也算是想学点前端相关技术吧,至少弄个简单静态页面应该不难。技术选型方面,Vue的渐进式特点更友好,又是国人领导开发的,于是就想着找个基于Vue的静态页面框架。Vuepress当然不错,然而那时vitepress已经发布一段时间了,虽然还是0.x版本。我向来是有些技术强迫症的,要弄就弄最新最好——于是就毅然选了Vitepress.
一开始是照着vitepress文档在Github Pages上部署了个简易页面,然后想着怎么魔改成适合博客的样子。一圈搜索之后,找到了airene/vitepress-blog-pure,看demo基本就是我想要的效果了。所以就直接抄了过来,当时也没fork,就直接复制粘贴相关的样式和代码到我已经部署的仓库上,然后魔改了下logo和颜色,添加了katex支持就算有了个正式博客了。
这次重构前的魔改
类型
我主要写C++/Rust比较多嘛,写js的时候一个对象打个.居然不能提示它有什么可以用的成员对我来说简直不能接受。于是花了些时间标注了类型,力求语法提示别挂掉。史前时代的vitepress不导出它的默认主题所用的config类型,当时我还照着文档手造了不少类型(当然现在已经改掉啦)。
评论系统
原主题是使用utterance来做评论的,并且相关评论控件还得刷新整个页面以支持路由切换和夜间主题切换。
因为之前是用issue来当博客嘛,utterance我还是知道的,但在那个时间点github多了discussion标签,相应的giscus出现了。我觉得giscus显然是更好的方案:不会污染issue内容,支持楼中楼回复。
读了几遍vitepress文档,我搞清楚了获取路由和夜间模式开启状态的方式。查了下刷新vue组件的方法,知道v-if之后就简单更新了评论组件,并默认开启所有页面评论了。
那时候
@giscus/vue不会随着夜间模式切换改自己的颜色,所以我只好自己用<component>包了一个评论控件。最近重构时发现这问题修复了,所以换回了@giscus/vue,切换夜间模式不用重新刷新组件了。
KaTeX
vitepress史前时代没有数学公式支持,然而数学公式支持对我来说又是必备需求,没办法找了点资料用KaTeX给博客加了公式支持。虽然后来vitepress内置MathJax3的支持了,但因为dev模式占内存更少不会OOM以及我更喜欢KaTeX的公式渲染样式的关系,就没有换了。
那时找不着有良好类型支持的markdown-it-katex插件,索性就自己写了个扔仓库里了。另外,使用KaTeX的话,vitepress自带的右侧目录生成在遇到含有数学公式的标题时会炸,所以还patch了一下默认主题的outline.js。(虽然不管怎么样,复杂公式标题的目录生成效果都不太好就是了,但简单的公式还是能看的)
自己加的两个小控件
闲的没事干给博客还加了嵌入推文和图片滑动比较的两个小控件,实际上也没咋在博客里用过。预想中是会写点图形相关的文章,结果到现在也没写成一篇,倒是杂七杂八的东西写了不少。
重构!
主页生成的方式
airene/vitepress-blog-pure其实问题不少,又是在vitepress的史前时代写的,我照抄当然也继承了不少问题。主页生成方式就是其中之一。
原来的做法是用fs-extra去扫描相关路径的markdown文件,自己生成一个post列表,然后按照设定的每页文章数量来分页。分页的办法也很简单粗暴:有几页就生成几个markdown文件,然后用一个手搓的长得像分页器的按钮序列来跳转。实际上vitepress现在已经提供了createContentLoader函数用来索引博客文章,而分页的话也不必用生成多个markdown这种方式:可以直接存个当前页码的引用,然后用v-for动态生成,省去页面跳转的开销。
/// posts.data.ts
import { createContentLoader } from 'vitepress'
import type { Post } from '.vitepress/env'
export declare const data: Post[]
export default createContentLoader('posts/*.md', {
transform(raw): Post[] {
return raw
.map(({ url, frontmatter }) => {
const date = frontmatter.date ? new Date(frontmatter.date) : new Date()
frontmatter.date = date.toISOString().split('T')[0]
frontmatter.title = frontmatter.title || '无标题'
return { frontMatter: frontmatter as Post['frontMatter'], regularPath: url }
})
.sort((a: Post, b: Post) => {
return a.frontMatter.date > b.frontMatter.date ? -1 : 1
})
},
})<template>
<div
v-for="(article, index) in pagePosts"
:key="index"
class="post-list"
>
<!-- v-for生成Post列表,略 -->
</div>
<!-- 分页器 -->
<div class="pagination-container">
<NPagination
v-model:page="pageCurrent"
:page-count="pagesNum"
:page-slot="5"
size="large"
></NPagination>
</div>
</template>
<script setup lang="ts">
/// 省略无关部分
const props = defineProps<{
posts: Array<Post>
pageSize?: number
}>()
const pagesNum = Math.ceil(props.posts.length / props.pageSize)
const pagePosts = computed(() => {
const start = (pageCurrent.value - 1) * props.pageSize
const end = start + props.pageSize
return props.posts.slice(start, end)
})
const pageCurrent = ref(1)
</script>这种方式有个显著的好处:之前的方式相当于hack了vitepress的构建,vite的hmr是不知道这一过程的。结果导致在dev的过程中,主页的文章标题、文章描述等需要重新生成page_xx.md的内容不会被hmr刷新,必须得重启dev server才能看到修改结果。采用新的主页生成方式后可以实时看到相应的变化了。
控件库:Naive-UI
你会注意到我使用了一个来自naive-ui的分页器控件。没有控件库全自己写基本控件也太痛苦了,所以我决定加入基本的控件库方便以后扩展。其实一开始我是打算使用vuetify的,然而它的分页器组件在用到主页上时会被vitepress的内置样式给影响,导致出现奇怪的显示效果。虽然有解决方案:使用vp-raw标记,然后用postcss来后处理。但是这个能让构建结果正常,但dev server上看起来还是样式崩坏的样子,最后还是放弃了。
在vitepress里使用naive-ui还挺麻烦的,按官方文档给的说明需要写入一大堆代码,我现在也没看太懂是在干啥()。另外给的例子没有考虑夜间模式的问题,我稍微看了看,发现需要多传个参数给 NConfigProvider,顺便回了相关issue。
有了控件库,实现一些简单小功能方便不少。比如,在aside上加一个返回上一页的按钮:
主页样式
一直以来有个主页样式的问题困扰着我:
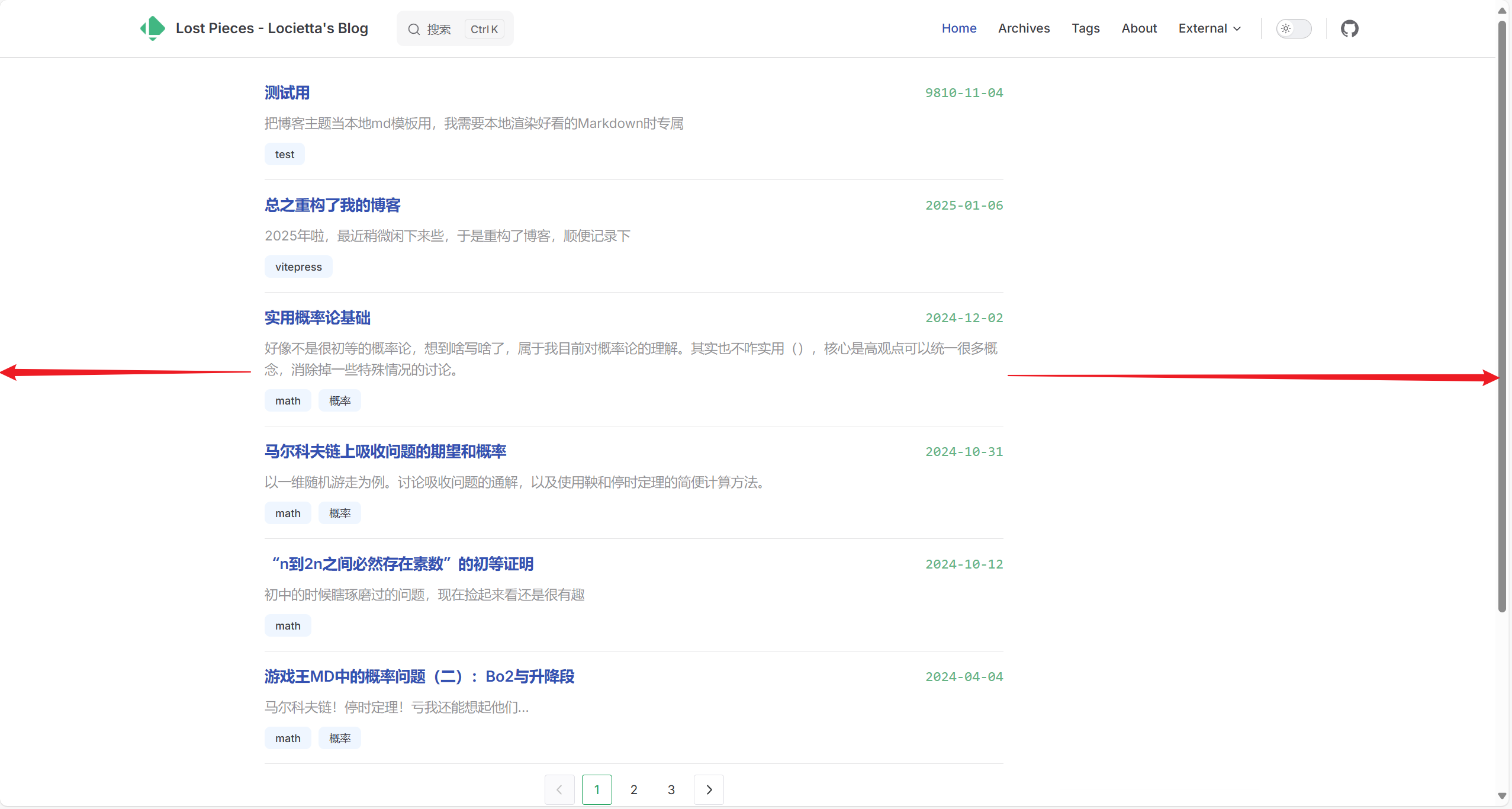
明显会发现左右不一样宽,这个问题其实在airene中是有处理的:hack相应的样式,把文章显示模式设成display: block然后再令目录的显示位置变为position: fixed手动去调位置。最后确实实现了居中显示的效果,然而文章目录的位置又感觉太靠右了,很不好看。
仔细想想,其实是因为有个隐藏的目录占据了空间,只要让没必要显示目录的页面关掉目录元素的生成就行了。最后,在所有的非文章页面的frontmatter里头加了aside: false,关掉了右侧目录的生成,结果确实使主页居中了。
原来的hack就只剩下调节文章显示宽度的作用了(不过原来display: block的情况好像调max-width也没效果就是)。
/* @hack.css */
/* Hack for wider page */
/* Pages w/o aside */
.VPDoc .content {
max-width: 60rem !important;
}
/* Pages w/ aside */
.VPDoc.has-aside .content-container {
max-width: 60rem !important;
}
/* Overall width for content+aside */
.VPContent .container {
max-width: 72rem !important;
}自动添加标题
新版vitepress支持了本地搜索,不必再配置algolia了,然而airene原来使用# { { $frontmatter.title } }避免重复书写标题的方式对搜索功能不是很友好(搜索时标题会显示为# { { $frontmatter.title } })。
我又不想手写标题,本来是想在vite构建的时候用hook自动加上标题,然而看了圈文档没找到合适的hook,转念一想,这功能可以用markdown-it插件的形式来实现,代码也并不困难:
/// @markdown-it-append-title.ts
import type MarkdownIt from 'markdown-it'
import matter from 'gray-matter'
export default function appendTitlePlugin(md: MarkdownIt) {
const old_render = md.render
md.render = (src, env) => {
const { data, content } = matter(src)
if (data.not_append_title) return old_render(src, env)
if (data.title) {
src = `# ${data.title}\n\n${content}`
}
return old_render(src, env)
}
}然后在config.ts里引入相关插件就好了:
import appendTitlePlugin from './markdown-it-append-title'
export default defineConfigWithTheme<ThemeConfig>({
markdown: {
config: (md) => {
md.use(appendTitlePlugin)
},
},
})这样就能自动把frontmatter里的title插入到文章开头了。
如果不要求文章页面显示标题的话,其实可以考虑修改search选项的_render()钩子。然而它只改搜索索引器看到的内容,不会影响实际页面渲染。我感觉有点bug-prone,而且我确实想要文章页面显示标题,所以各方面不如使用markdown-it插件。
改善中文搜索
改了标题生成相关后,我又发现自带的mini-search对中文搜索的支持不太好,于是又去研究了一下怎么改。简单搜索后找到了lucaong/minisearch#201,查了查文档感觉点赞最多的那个solution其实写得有些意义不明:为啥要分别配options的tokenize和searchOptions的processTerms,尤其processTerms实际上是令匹配到token的一部分也能算匹配成功,这显然没啥道理。
我设想搜索的人应该是输入一个关键词,然后查找相关的文章,本来也不会有人大段粘贴一段话过来。这种情况下,应该排除掉所有只匹配一部分搜索词的内容才对。比如我在搜索框输入“泛函”,按他的方案,我会搜出一大堆“函数”相关的内容,这显然不好。但不修改搜索方式也不好,默认情况下输入“泛函”啥也搜不出来,所以尝试了下我还是弄了个自己的设置。
...
export default defineConfig({
...
themeConfig: {
search: {
options: {
miniSearch: {
// Ref: https://github.com/lucaong/minisearch/issues/201
// The solution there doesn't quite make sense though, I tweaked it a bit.
options: {
tokenize: (text) => {
text = text.toLowerCase()
// TODO: better CJK tokenizer
// NOTE: How to inject dependency (n-gram etc.) into here? `tokenize` will ignore top-level import somehow,
// and it can't be made async which means we can't dynamic import.
const segmenter = Intl.Segmenter && new Intl.Segmenter('zh', { granularity: 'word' })
if (!segmenter) return [text] // firefox?
return Array.from(segmenter.segment(text), ({ segment }) => segment)
},
},
searchOptions: {
combineWith: 'AND',
// don't split search word, user searching "泛函" shouldn't get "广泛" or "函数"
// XXX: This is a hack, we should probably use a better CJK tokenizer
tokenize: (text) => [text.toLowerCase()],
fuzzy(term) {
// disable fuzzy search if the term contains a CJK character
// so searching "函数式" will not contain results only matching "函数"
const CJK_RANGE =
'\u2e80-\u2eff\u2f00-\u2fdf\u3040-\u309f\u30a0-\u30fa\u30fc-\u30ff\u3100-\u312f\u 3200-\u32ff\u3400-\u4dbf\u4e00-\u9fff\uf900-\ufaff'
const CJK_WORD = new RegExp(`[${CJK_RANGE}]`)
if (CJK_WORD.test(term)) return false
return true
},
},
},
},
},
},
...
});实话说效果也一般,最好还是应该用更好的CJK分词,而不是浏览器自带的Intl.Segmenter分词。但我尝试用n-gram的时候发现这边的tokenize一类的函数回调接口似乎不能访问config.ts里import引入的内容,没想出好的解决方案,所以就搁置了。

markdown-it-wordless
第一段
第一段,但是换行了
第二段默认的markdown渲染器会把换行渲染为半角空格,这在英文里是合理的,单词和单词之间本来就该有空格。但中文里头,好好一段话中间突然多出个空格,这就不对了。在上面的例子里,第一段的两行会被渲染为第一段 第一段,但是换行了,中间多出个空格。
有现成的markdown-it-wordless插件可以解决这个问题。在config.ts里简单加一下配置就好了,考虑到用不到其他语言,所以就只开启了中文和日文的支持。
import { wordless, chineseAndJapanese, type Options } from 'markdown-it-wordless'
export default defineConfig({
markdown: {
config: (md) => {
md.use<Options>(wordless, { supportWordless: [chineseAndJapanese] })
},
},
})lint & tsconfig & ...
其实之前是有配置eslint的,然而我瞎升级依赖,新版的eslint不认旧的配置文件,所以这个lint好长一段时间都是形同虚设。趁着重构赶紧改改,把.eslintrc.cjs迁移到eslint.config.js,换上新的flat配置,再把没用的各种lint插件删掉。最后用husky加了个pre-commit hook,每次commit前自动lint和format。
tsconfig.json这边也精简了一下,引入@vue/tsconfig,把compilerOptions里没用的配置删掉,跟进新的最佳实践。
另外也把lock文件传上来了,之前一直以为lock文件和build文件夹是类似的东西,没必要传。最近惊觉lock文件其实应该传,不然依赖版本会乱,这次也补上。也算是修正了个错误观念。
之后干啥
花了大力气重构,之后肯定要好好写博客了。
其实还有个做成npm包发布的事情,不过反正也就自己用用,现在也不着急。